
Gestion des sources de données
Vue d'ensemble des sources de données
La page Sources de données représente l'espace central de gestion des connaissances de la plateforme. Elle affiche l'ensemble des sources documentaires qui alimentent vos Apps, permettant une vue globale et une gestion simplifiée de votre base de connaissances.
Interface principale
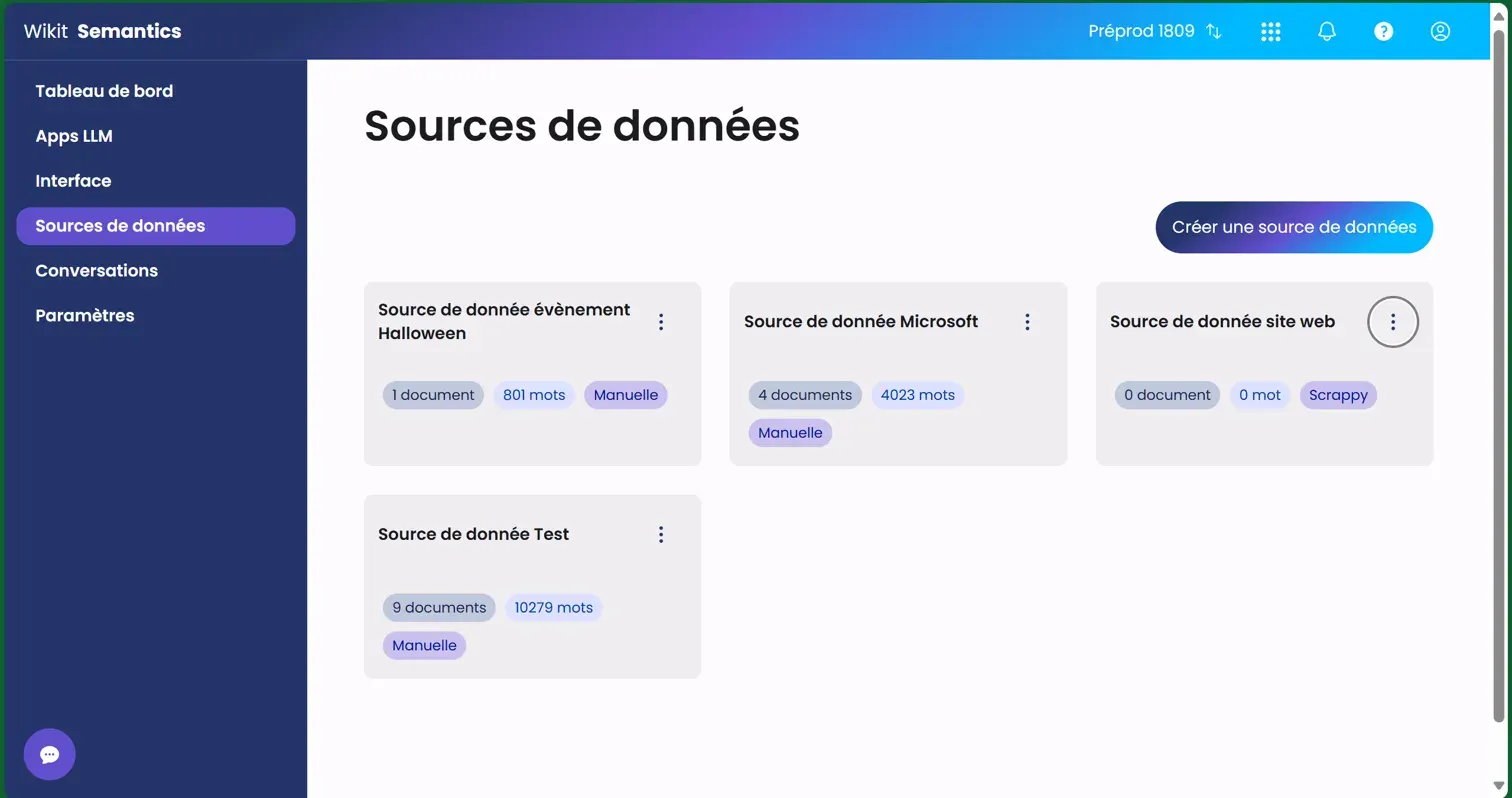
L'interface se compose d'une grille de cartes, chacune représentant une source de données distincte. En haut de la page, un bouton bleu "Créer une source de données" permet d'ajouter de nouvelles sources à votre collection.
Les cartes sources de données
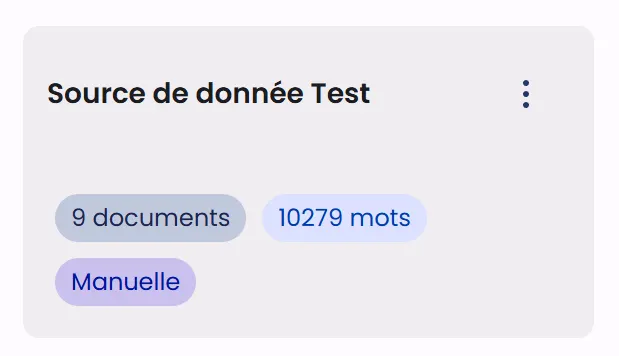
Chaque source de données est représentée par une carte qui contient les informations essentielles :
Informations générales
- Le nom de la source apparaît en titre de la carte
- Un compteur indique le nombre de documents contenus dans la source
- Le volume total de contenu est affiché en nombre de mots
- Une étiquette identifie le type de la source (Manuelle, Connecteur, etc.)
Menu de gestion
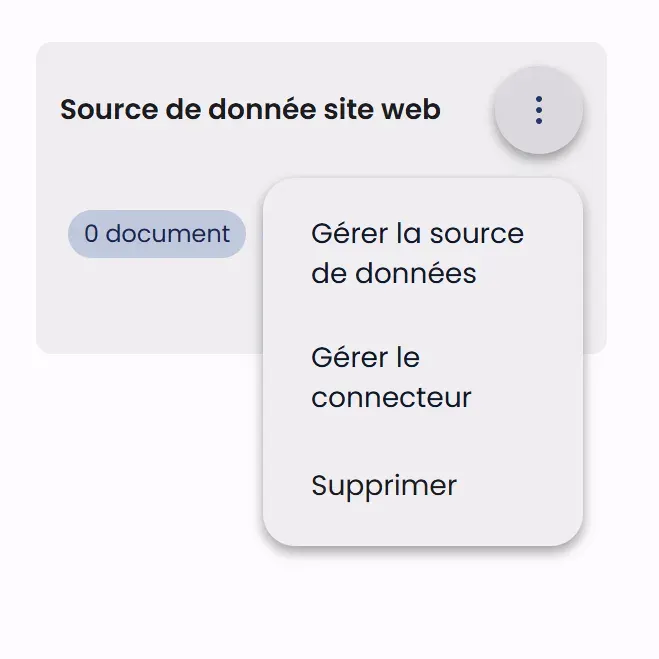
Un menu à trois points (⋮) en haut à droite de chaque carte donne accès aux options de gestion :
- L'option "Gérer la source de données" permet d'accéder aux paramètres et au contenu
- "Gérer le connecteur" offre le contrôle sur la méthode d'importation des données (pour les sources de type connecteur)
- "Supprimer" permet de retirer la source de l'espace de travail
Types de sources disponibles
La plateforme prend en charge plusieurs types de sources de données, chacun adapté à des besoins spécifiques :
Sources manuelles
Ces sources permettent l'ajout direct de documents. Elles sont identifiées par l'étiquette "Manuelle" et sont particulièrement adaptées pour les documents internes ou spécifiques.
Sources connecteurs
Ces sources sont alimentées par un connecteur.
Ajout et configuration de sources de données
Création d'une source de données

La page de création d'une source de données permet de configurer une nouvelle source qui alimentera vos applications LLM en connaissances. Elle se compose de plusieurs champs de configuration essentiels.
Champs de configuration
Nom
Le champ nom permet d'identifier votre source de données. Cette identification est limitée à 40 caractères pour garantir une présentation claire dans l'interface.
Description
Un champ texte qui permet de décrire en détail l'usage et le contenu de votre source de données. Cette description facilite la compréhension du rôle de la source par tous les utilisateurs.
Origine
L'origine de la source peut être définie selon deux options :
- Manuelle : Pour l'ajout direct de documents
- Connecteur : Pour une connexion automatisée à une source externe
Modèles d'embeddings
Une liste déroulante permettant de sélectionner le modèle de vectorisation qui sera utilisé pour traiter les documents de cette source.
Création de liens publics
Un interrupteur permettant d'activer ou désactiver la possibilité de créer des liens publics vers les documents de cette source. Par défaut, cette option est désactivée.
Boutons d'action
La page propose deux options en bas :
- Annuler : Pour abandonner la création
- Créer : Pour valider la création de la source avec les paramètres configurés
Détails de la source de données
La page de détails d'une source de données est organisée en trois onglets principaux permettant de consulter et gérer tous les aspects de la source : Informations, Documents, et Paramètres avancés.
Onglet Informations
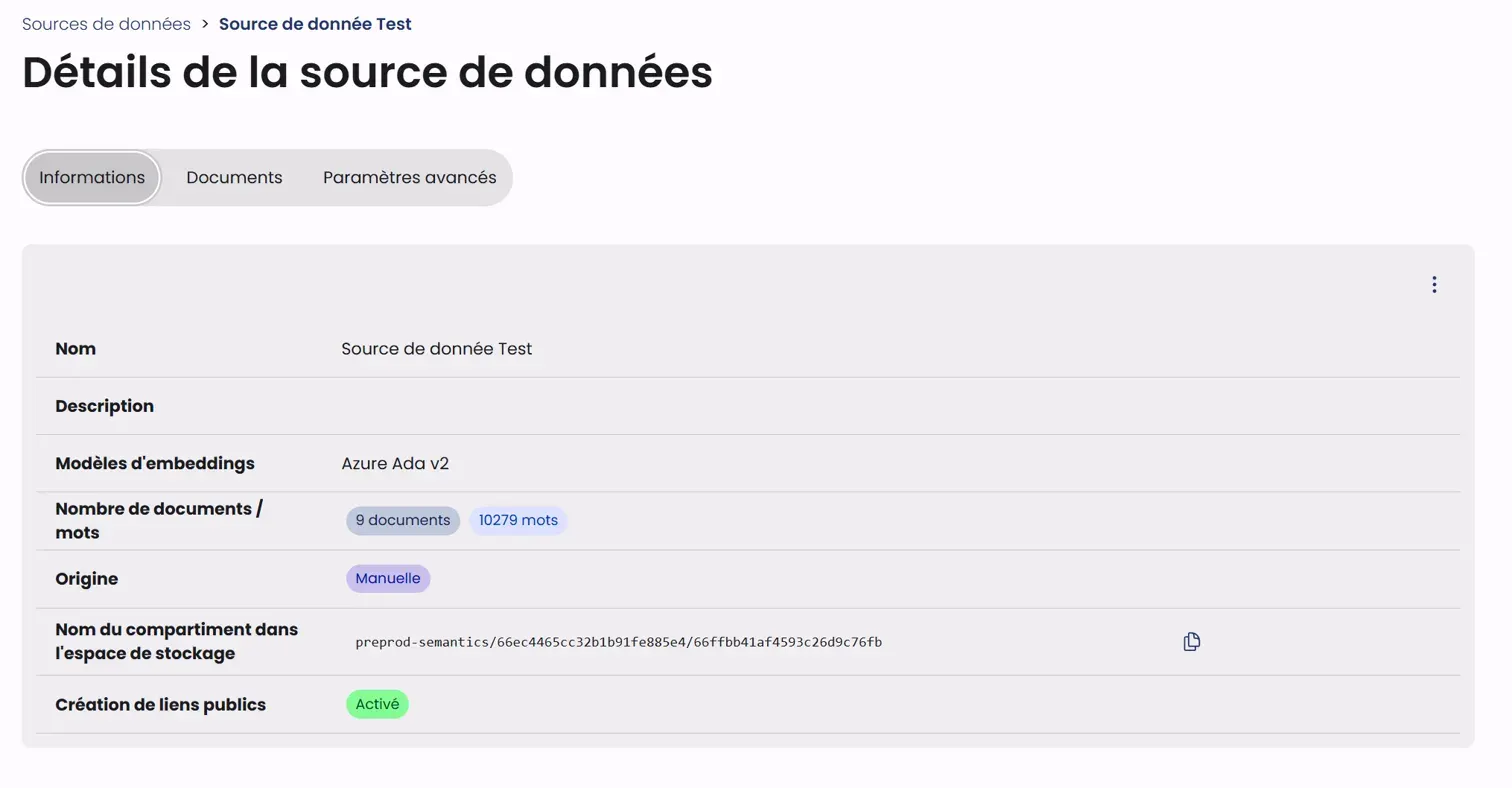
L'onglet Informations présente les caractéristiques principales de la source de données :
- Nom : Le nom identifiant la source
- Description : La description détaillée de la source
- Modèles d'embeddings : Le modèle utilisé pour l'analyse des documents (ex: Azure Ada v2)
- Nombre de documents/mots : Les statistiques de contenu (nombre de documents et total des mots)
- Origine : Le type d'import des documents (Manuelle ou via Connecteur)
- Nom du compartiment : L'identifiant technique de stockage
- Création de liens publics : L'état d'activation des liens publics (Activé/Désactivé)
Onglet Documents
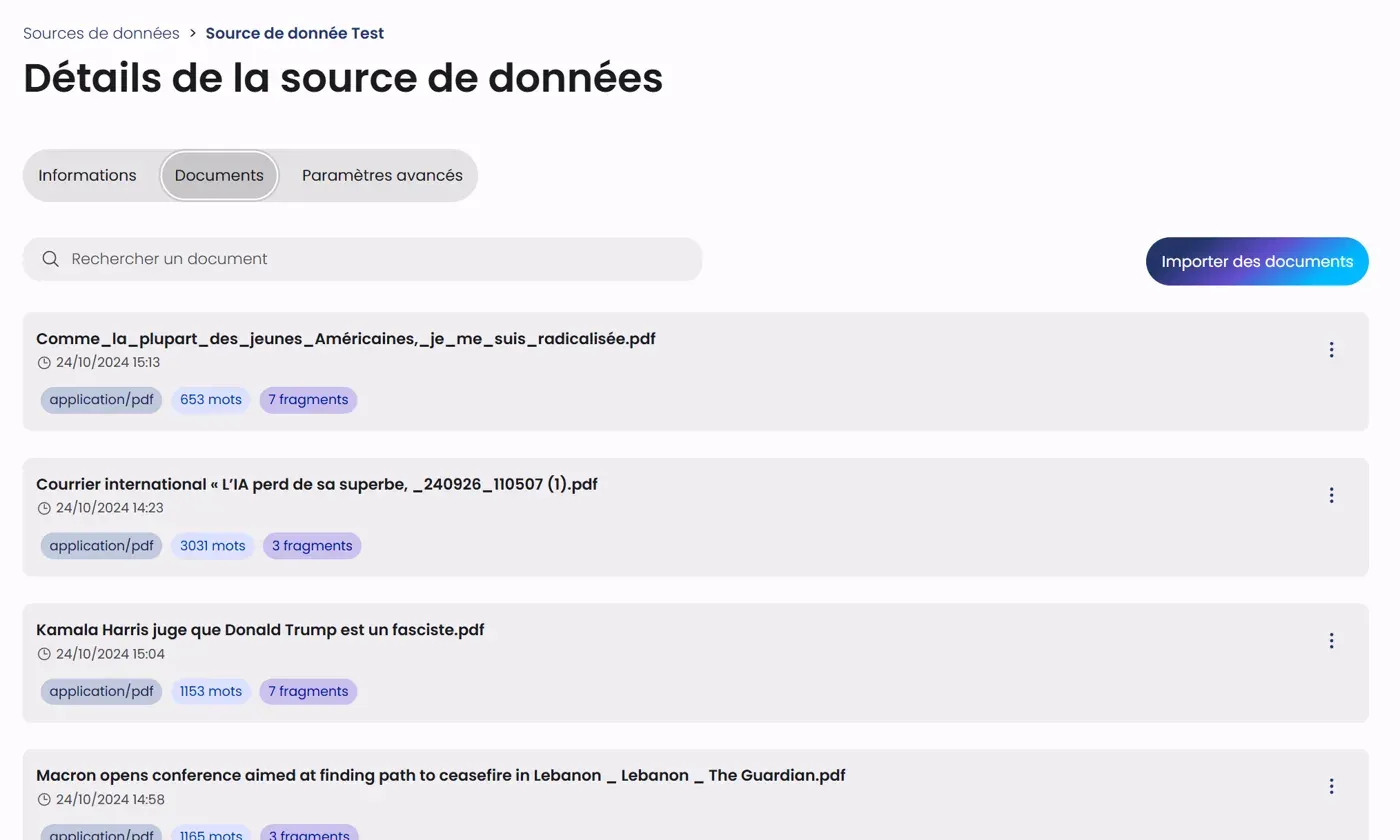
L'onglet Documents permet de gérer le contenu de la source de données:
Barre d'outils
- Une barre de recherche pour filtrer les documents
- Un bouton "Importer des documents" pour ajouter du contenu
Liste des documents
Chaque document est présenté avec :
- Le nom du fichier
- La date et l'heure d'import
- Le type de fichier (ex: application/pdf)
- Le nombre de mots
- Le nombre de fragments
- Un menu d'actions (⋮)
Onglet Paramètres avancés

L'onglet Paramètres avancés contient les stratégies de fragmentation des documents :
Stratégies de fragmentation
Un tableau présentant la stratégie de fragmentation utilisé par Wikit Semantics pour chaque type de document :
- Documents Microsoft Word (*.docx) : Par nombre de caractères
- Documents PDF (*.pdf) : Par titre (Recommandé)
- Fichiers texte (*.txt) : Par nombre de caractères
- Fichiers Markdown (*.md) : Par titre (Recommandé)
- Pages Web (*.html) : Par titre (Recommandé)
- Fichiers JSON (*.json) : Par titre (Recommandé)
Chaque stratégie peut être modifiée via l'icône crayon à droite du tableau.
Cette configuration permet d'optimiser la manière dont les documents sont découpés pour l'analyse, en fonction de leur format et de leur structure.